

Building Information Models are essentially databases, containing elements with geometric information and data attached. Building up through the years, a collection of those models becomes a sort of huge dataset that could be used for machine learning purposes. We aimed to create a practical way of extracting data from models coming of the most popular BIM software.
Dynamo for Revit allows to access all kinds of data and manipulate them. Some nodes allow the data to come out of Revit, in various formats. Some nodes allow the user to access other Revit files. However, I didn’t find an effective way to extract data on dozens of models effectively : the current methods force the user to open them all at once, then perform the data extraction, and finally close them all at once. If only one model wouldn’t work for some reason, the whole process would be cancelled.
Furthermore, it is required to create a new entire graph for each data extraction. My aim was therefore to create an easy to use, scalable way to get the data you want. This article presents the first version of this work.
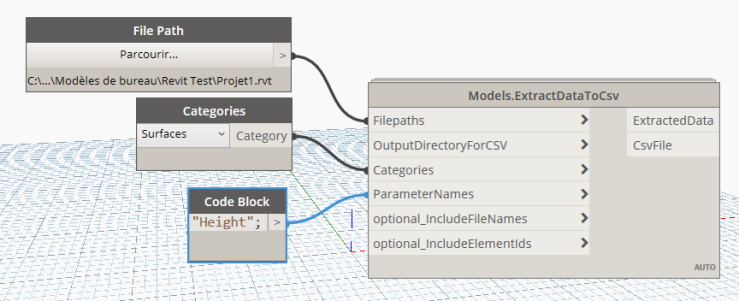
Essentially, it allows the user to select a couple of things :
- the models to access (using their file paths)
- the object categories to extract data from
- the parameters that hold the desired data on those objects
- where to extract the data to
It then takes care of the rest. The node will loop through each of Revit files, open them, look for the desired objects and parameters and store the info, before closing them. It then outputs a .csv file, which is a standard way of storing data and an easy to use format for everybody : it opens in Excel, but can also be read by lots of software libraries. Of course, it also outputs the data in Dynamo !
It is a first version, and I am looking to improve it. The first ideas coming to my mind :
- It only works with Categories
- In the future, a main node could be fed with ‘Datasets’ nodes, containing different sets of objects and parameters, so as to perform multiple extractions at once
- It could be also be fed functions aiming to get specific data not accessible with a simple parameter lookup (like the coordinates of the object in the file)
Some of this improvements are fairly easy to implement… Stay tuned ! Available in the Morpheus package.
Feel free to share what kind of improvements you would like to see.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #Made by Jonathan ATGER, 2019 | |
| import clr | |
| #clr.AddReference('ProtoGeometry') | |
| #from Autodesk.DesignScript.Geometry import * | |
| import sys | |
| pyt_path = r'C:\Program Files (x86)\IronPython 2.7\Lib' | |
| sys.path.append(pyt_path) | |
| import System | |
| # Import Element wrapper extension methods | |
| clr.AddReference("RevitNodes") | |
| import Revit | |
| clr.ImportExtensions(Revit.Elements) | |
| # Import DocumentManager and TransactionManager | |
| clr.AddReference("RevitServices") | |
| import RevitServices | |
| from RevitServices.Persistence import DocumentManager | |
| #from RevitServices.Transactions import TransactionManager | |
| #doc = DocumentManager.Instance.CurrentDBDocument | |
| uiapp = DocumentManager.Instance.CurrentUIApplication | |
| app = uiapp.Application | |
| import csv | |
| import time | |
| # Import RevitAPI | |
| clr.AddReference("RevitAPI") | |
| import Autodesk | |
| from Autodesk.Revit.DB import * | |
| #inputs | |
| if isinstance(IN[0], list) : filepaths = IN[0] | |
| else : filepaths = [IN[0]] | |
| currentdocument = IN[1] | |
| directorypath = IN[2] | |
| if isinstance(IN[3], list) : categories = IN[3] | |
| else : categories = [IN[3]] | |
| if isinstance(IN[4], list) :params = IN[4] | |
| else : params = [IN[4]] | |
| getmodelname = IN[5] | |
| getid = IN[6] | |
| #convert paths to usable modelpaths | |
| paths = [] | |
| if IN[0] != None : | |
| for p in filepaths : | |
| modelpath = ModelPathUtils.ConvertUserVisiblePathToModelPath(p) | |
| paths.append(modelpath) | |
| #Setup list for the output of the node | |
| out = [] | |
| headers = [] | |
| unreaddocuments = [] | |
| #create headers for csv file | |
| if getmodelname == True : | |
| headers.append("File Name") | |
| if getid == True : | |
| headers.append("Id") | |
| for c in params : | |
| headers.append(c) | |
| out.append(headers) | |
| #function gets all elements of a category in a document | |
| def categoryelementscollection (category, doc) : | |
| #filter | |
| filter = ElementCategoryFilter(System.Enum.ToObject(BuiltInCategory, c.Id)) | |
| #Collector filtering out types | |
| col = FilteredElementCollector(doc).WherePasses(filter).WhereElementIsNotElementType().ToElements() | |
| return col | |
| #function collects data from elements | |
| def extractdata (doc, collector, getmodelname, getid, params) : | |
| if getmodelname == True : | |
| #add document name | |
| pathname = doc.PathName | |
| name = pathname.split("\\")[-1] | |
| data = [] | |
| for e in collector : | |
| elementdata = [] | |
| if getmodelname == True : | |
| elementdata.append(name) | |
| if getid == True : | |
| elementdata.append(e.Id) | |
| for p in params : | |
| try : | |
| #lookup for the data and store it as a string | |
| param = e.LookupParameter(p).AsValueString() | |
| if param == None : | |
| param2 = e.LookupParameter(p).AsString() | |
| elementdata.append(param2) | |
| else : | |
| elementdata.append(param) | |
| except : | |
| elementdata.append("No parameter with the given name") | |
| #append the elementdata to the output | |
| data.append(elementdata) | |
| return data | |
| # set document opening options | |
| options = OpenOptions() | |
| options.DetachFromCentralOption = DetachFromCentralOption.DetachAndPreserveWorksets | |
| try : | |
| #Main loop : cycle through all specified documents | |
| for i in paths : | |
| try : | |
| #open revit document | |
| opendoc = app.OpenDocumentFile(i, options) | |
| for c in categories : | |
| col = categoryelementscollection(c, opendoc) | |
| data = extractdata (opendoc, col, getmodelname, getid, params) | |
| for elementdata in data : | |
| out.append(elementdata) | |
| #Close document | |
| opendoc.Close(False) | |
| except : | |
| unreaddocuments.append(i) | |
| # data extraction on current document | |
| if currentdocument == True : | |
| try : | |
| doc = DocumentManager.Instance.CurrentDBDocument | |
| for c in categories : | |
| col = categoryelementscollection(c, doc) | |
| data = extractdata (doc, col, getmodelname, getid, params) | |
| for elementdata in data : | |
| out.append(elementdata) | |
| except : | |
| unreaddocuments.append("Current document") | |
| #csv filename | |
| csvfilename = directorypath + '\\modeldata_' + time.strftime("%Y%m%d_%H%M%S") + '.csv' | |
| #main output | |
| OUT = out[1:], csvfilename, unreaddocuments | |
| with open(csvfilename, mode='wb') as csv_file : | |
| csv_filewriter = csv.writer(csv_file, delimiter=';', quotechar='"', quoting=csv.QUOTE_MINIMAL) | |
| for line in out : | |
| csv_filewriter.writerow(line) | |
| except: | |
| # if error accurs anywhere in the process catch it | |
| import traceback | |
| errorReport = traceback.format_exc() | |
| OUT = errorReport |
